| assets | ||
| audio | ||
| datasets | ||
| models | ||
| recognition | ||
| scripts | ||
| text | ||
| utils | ||
| web | ||
| .gitignore | ||
| app.py | ||
| DISCLAIMER | ||
| download.py | ||
| eval.py | ||
| hparams.py | ||
| LICENSE | ||
| README.md | ||
| README_ko.md | ||
| requirements.txt | ||
| run.sh | ||
| synthesizer.py | ||
| train.py | ||
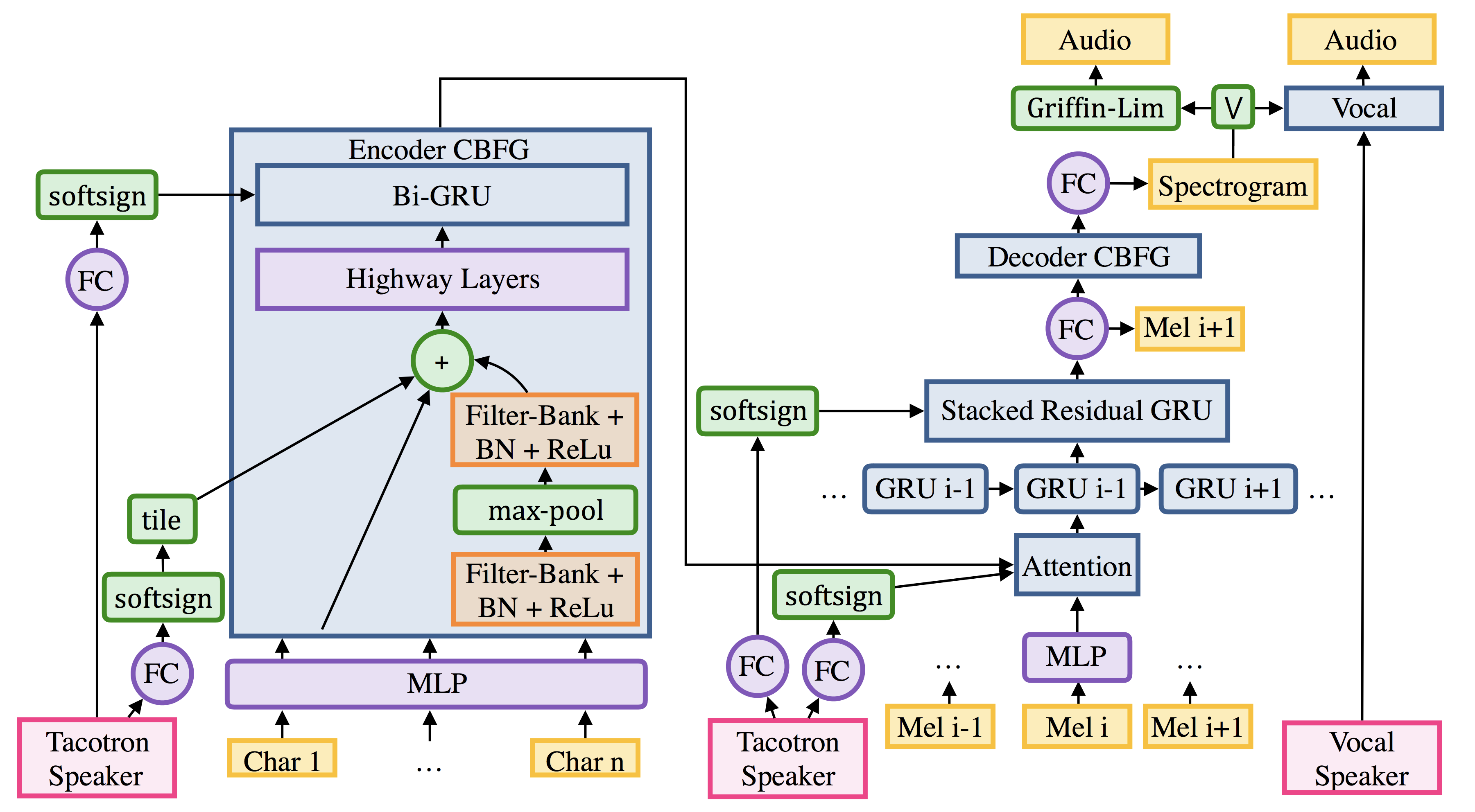
Multi-Speaker Tacotron in TensorFlow
[한국어 가이드]
TensorFlow implementation of:
- Deep Voice 2: Multi-Speaker Neural Text-to-Speech
- Listening while Speaking: Speech Chain by Deep Learning
- Tacotron: Towards End-to-End Speech Synthesis
Samples audios (in Korean) can be found here.
Prerequisites
- Python 3.6+
- Tensorflow 1.3
Usage
1. Install prerequisites
After preparing Tensorflow, install prerequisites with:
pip3 install -r requirements.txt
If you want to synthesize a speech in Korean dicrectly, follow 2-3. Download pre-trained models.
2-1. Generate custom datasets
The datasets directory should look like:
datasets
├── jtbc
│ ├── alignment.json
│ └── audio
│ ├── 1.mp3
│ ├── 2.mp3
│ ├── 3.mp3
│ └── ...
└── YOUR_DATASET
├── alignment.json
└── audio
├── 1.mp3
├── 2.mp3
├── 3.mp3
└── ...
and YOUR_DATASET/alignment.json should look like:
{
"./datasets/YOUR_DATASET/audio/001.mp3": "My name is Taehoon Kim.",
"./datasets/YOUR_DATASET/audio/002.mp3": "The buses aren't the problem.",
"./datasets/YOUR_DATASET/audio/003.mp3": "They have discovered a new particle.",
}
After you prepare as described, you should genearte preprocessed data with:
python -m datasets.generate_data ./datasets/YOUR_DATASET/alignment.json
2-2. Generate Korean datasets
You can generate datasets for 3 public Korean figures including:
- Sohn Suk-hee: anchor and president of JTBC
- Park Geun-hye: a former President of South Korea
- Moon Jae-in: the current President of South Korea
Each dataset can be generated with following scripts:
./scripts/prepare_son.sh # Sohn Suk-hee
./scripts/prepare_park.sh # Park Geun-hye
./scripts/prepare_moon.sh # Moon Jae-in
Each script execute below commands. (explain with son dataset)
-
To automate an alignment between sounds and texts, prepare
GOOGLE_APPLICATION_CREDENTIALSto use Google Speech Recognition API. To get credentials, read this.export GOOGLE_APPLICATION_CREDENTIALS="YOUR-GOOGLE.CREDENTIALS.json" -
Download speech(or video) and text.
python -m datasets.son.download -
Segment all audios on silence.
python -m audio.silence --audio_pattern "./datasets/son/audio/*.wav" --method=pydub -
By using Google Speech Recognition API, we predict sentences for all segmented audios. (this is optional for
moonandparkbecause they already haverecognition.json)python -m recognition.google --audio_pattern "./datasets/son/audio/*.*.wav" -
By comparing original text and recognised text, save
audio<->textpair information into./datasets/son/alignment.json.python -m recognition.alignment --recognition_path "./datasets/son/recognition.json" --score_threshold=0.5 -
Finally, generated numpy files which will be used in training.
python3 -m datasets.generate_data ./datasets/son/alignment.json
Because the automatic generation is extremely naive, the dataset is noisy. However, if you have enough datasets (20+ hours with random initialization or 5+ hours with pretrained model initialization), you can expect an acceptable quality of audio synthesis.
2-3. Download pre-trained models
You can download a pre-trained models or generate audio. Available models are:
-
Single speaker model for Sohn Suk-hee.
python3 download.py son -
Single speaker model for Park Geun-hye.
python3 download.py park
After you donwload pre-trained models, you can generate voices as follows:
python3 synthesizer.py --load_path logs/son-20171015 --text "이거 실화냐?"
python3 synthesizer.py --load_path logs/park-20171015 --text "이거 실화냐?"
WARNING: The two pre-trained models are being made available for research purpose only.
3. Train a model
To train a single-speaker model:
python train.py --data_path=datasets/jtbc
python train.py --data_path=datasets/park --initialize_path=PATH_TO_CHECKPOINT
To train a multi-speaker model:
python train.py --data_path=datasets/jtbc,datasets/park
If you don't have good and enough (10+ hours) dataset, it would be better to use --initialize_path to use a well-trained model as initial parameters.
4. Synthesize audio
You can train your own models with:
python3 app.py --load_path logs/park-20171015 --num_speakers=1
or generate audio directly with:
python3 synthesizer.py --load_path logs/park-20171015 --text "이거 실화냐?"
Disclaimer
This is not an official DEVSISTERS product. This project is not responsible for misuse or for any damage that you may cause. You agree that you use this software at your own risk.
References
- Keith Ito's tacotron
- DEVIEW 2017 presentation (Korean)
Author
Taehoon Kim / @carpedm20